
KubeVela 1.7 版本已经正式发布一段时间,在此期间 KubeVela 正式晋级成为了 CNCF 的孵化项目,开启了一个新的里程碑。而 KubeVela 1.7 本身也是一个转折点,由于 KubeVela 从一开始就专注于可扩展体系的设计,对于控制器核心功能的需求也开始逐步收敛,我们开始腾出手来更加专注于用户体验、易用性、以及性能。在本文中,我们将重点挑选 1.7 版本中的工作负载接管、性能优化等亮点功能进行介绍。
接管你的工作负载
接管已有的工作负载一直是社区里呼声很高的需求,其场景也非常明确,即已经存在的工作负载可以自然的迁移到 OAM 标准化体系中,被 KubeVela 的应用交付控制面统一管理,复用 VelaUX 的 UI 控制台功能,包括社区的一系列运维特征、工作流步骤以及丰富的插件生态。在 1.7 版本中,我们正式发布了该功能,在了解具体怎么操作之前,让我们先对其运行模式有个基本了解。
“只读” 和 “接管” 两种模式
为了适应不同的使用场景,KubeVela 提供了两种模式来满足你统一管理的需求,一种是只读模式,适用于内部已经有自建平台的系统,这些系统对于存量业务依旧具有主要的控制能力,而新的基于 KubeVela 的平台系统可以只读式的统一观测到这些应用。另一种是接管模式,适用于想直接做迁移的用户,可以把已有的工作负载自动的接管到 KubeVela 体系中,并且完全统一管理。
- “只读”(read-only)模式顾名思义,它不会对资源有任何“写”操作。使用只读模式纳管的工作负载,可以通过 KubeVela 的工具集(如 CLI、VelaUX)做可视化,满足统一查看、可观测方面的需求。与此同时,只读模式下生成的纳管应用被删除时,底下的工作负载资源也不会被回收。而底层工作负载被其他控制器会人为修改时,KubeVela 也可以观察到这些变化。
- “接管”(take-over)模式意味着底层的工作负载会被 KubeVela 完全管理,跟其他直接通过 KubeVela 体系创建出来的工作负载一样,工作负载的更新、删除等生命周期将完全由 KubeVela 应用体系控制。默认情况下,其他系统对工作负载的修改也就不再生效,会被 KubeVela 面向终态的控制循环改回来,除非你加入了其他的管理策略(如 apply-once)。
而声明接管模式的方法则使用 KubeVela 的策略(policy)体系,如下所示:
apiVersion: core.oam.dev/v1beta1
kind: Application
metadata:
name: read-only
spec:
components:
- name: nginx
type: webservice
properties:
image: nginx
policies:
- type: read-only
name: read-only
properties:
rules:
- selector:
resourceTypes: ["Deployment"]
在 “read-only” 策略中,我们定义了多种只读规则,如样例中只读选择器命中的资源是 “Deployment”,那就意味着只有对 Deployment 的资源是只读的,我们依旧可以通过运维特征创建和修改 “Ingress”、“Service” 等资源,而使用 “scaler” 运维特征对 Deployment 的实例数做修改则不会生效。
apiVersion: core.oam.dev/v1beta1
kind: Application
metadata:
name: take-over
spec:
components:
- name: nginx-take-over
type: k8s-objects
properties:
objects:
- apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
traits:
- type: scaler
properties:
replicas: 3
policies:
- type: take-over
name: take-over
properties:
rules:
- selector:
resourceTypes: ["Deployment"]
在“take-over”策略中,我们也包括了一系列的选择器,可以保证接管的资源是可控的。而上述的例子在不加“take-over”策略时,如果系统中已经有名为“nginx”的 Deployment 资源,则会运行失败,因为资源已经存在。一方面,接管策略保证了应用创建时可以将已经存在的资源纳入管理;另一方面,也可以复用之前已经存在的工作负载配置,只会将诸如 scaler 运维特征中对实例数的修改作为配置的一部分 “patch”到原先的配置上。
使用命令行一键接管工作负载
在了解了接管模式以后,你肯定会想是否有一种简便的方式,可以一键接管工作负载?没错,KubeVela 的命令行提供了这种简便方式,可以将诸如 K8s 常见的资源、“Helm”等工作负载一键接管,使用起来非常方便。具体而言,velaCLI 会自动去识别系统里的资源并将其组装成一个应用完成接管,我们在设计这个功能的核心原则是“资源的接管不能触发底层工作负载的重启”。
如下所示,默认情况下,使用 vela adopt会用“read-only”模式管理,只需指定要接管的原生资源类型、命名空间及其名称,就可以自动生成接管的 Application 对象。生成的应用 spec 跟集群中实际的字段严格一致。
$ vela adopt deployment/default/example configmap/default/example
apiVersion: core.oam.dev/v1beta1
kind: Application
metadata:
labels:
app.oam.dev/adopt: native
name: example
namespace: default
spec:
components:
- name: example.Deployment.example
properties:
objects:
- apiVersion: apps/v1
kind: Deployment
metadata:
name: example
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: example
template:
metadata:
labels:
app: example
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nginx
restartPolicy: Always
...
type: k8s-objects
- name: example.config
properties:
objects:
- apiVersion: v1
kind: ConfigMap
metadata:
name: example
namespace: default
type: k8s-objects
policies:
- name: read-only
properties:
rules:
- selector:
componentNames:
- example.Deployment.example
- example.config
type: read-only
目前支持的默认接管类型其名称和资源 API 对应关系如下:
- crd: ["CustomResourceDefinition"]
- ns: ["Namespace"]
- workload: ["Deployment", "StatefulSet", "DaemonSet", "CloneSet"]
- service: ["Service", "Ingress", "HTTPRoute"]
- config: ["ConfigMap", "Secret"]
- sa: ["ServiceAccount", "Role", "RoleBinding", "ClusterRole", "ClusterRoleBinding"]
- operator: ["MutatingWebhookConfiguration", "ValidatingWebhookConfiguration", "APIService"]
- storage: ["PersistentVolume", "PersistentVolumeClaim"]
如果想要把应用改成接管模式、并且直接部署到集群中,只需增加几个参数即可:
vela adopt deployment/default/example --mode take-over --apply
除了原生资源,vela 命令行也默认支持接管 Helm 应用创建的工作负载。
vela adopt mysql --type helm --mode take-over --apply --recycle -n default
如上述命令就会通过“接管” 模式管理 "default" 命名空间下名为“mysql”的 helm release,指定 --recycle可以在部署成功后把原来的 helm release 元信息清理掉。
接管后的工作负载就已经生成出了 KubeVela 的 Application,所以相关的操作就已经跟 KubeVela 体系对接,你可以在 VelaUX 界面上看到接管的应用,也可以通过 vela 命令行的其他功能查看、操作应用。
你还可以通过命令批量一键接管你命名空间的全部工作负载,根据 KubeVela 的资源拓扑关系能力,系统会自动识别关联的资源,形成一个完整的应用。对于 CRD 等自定义资源,KubeVela 也支持自定义关联关系的规则。
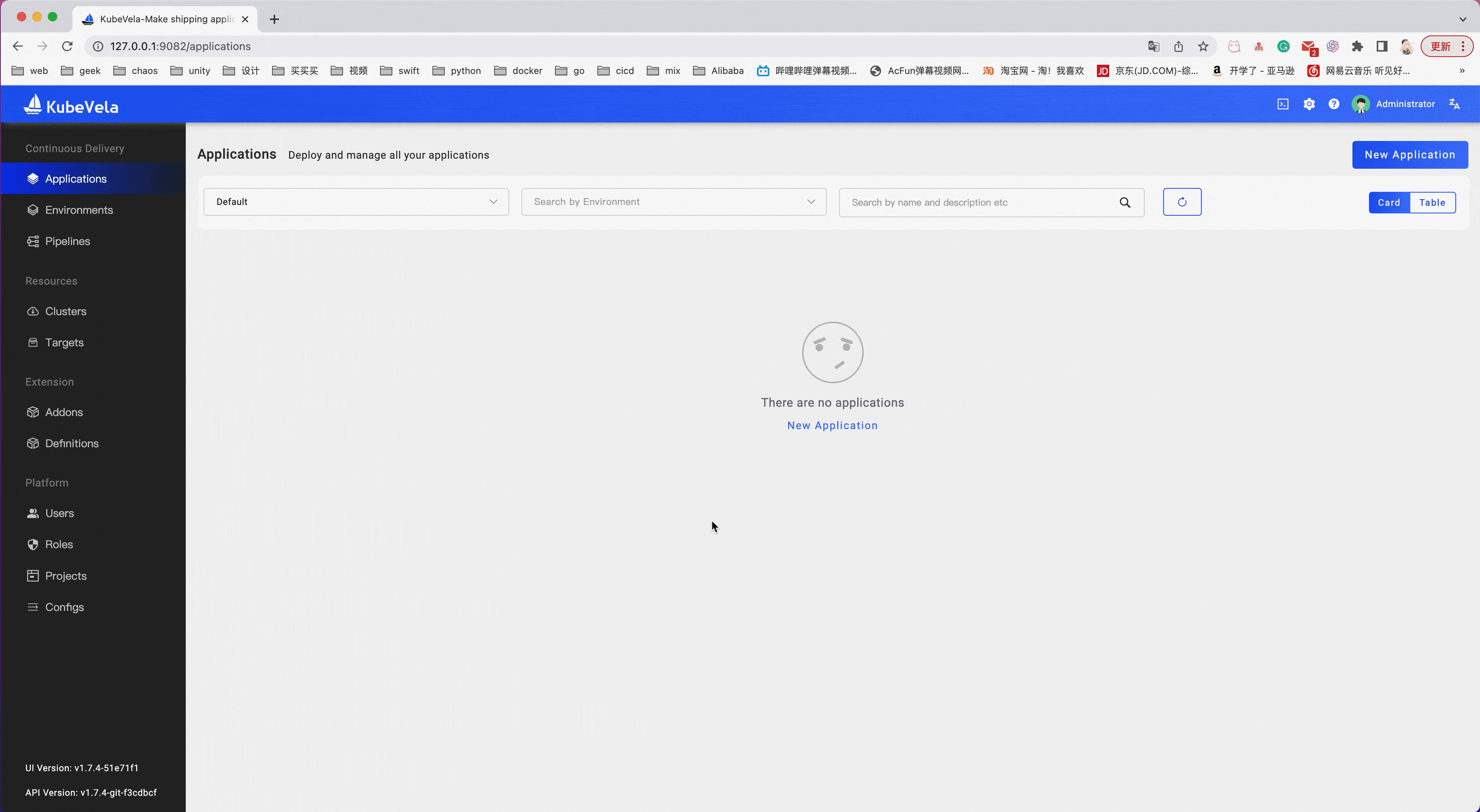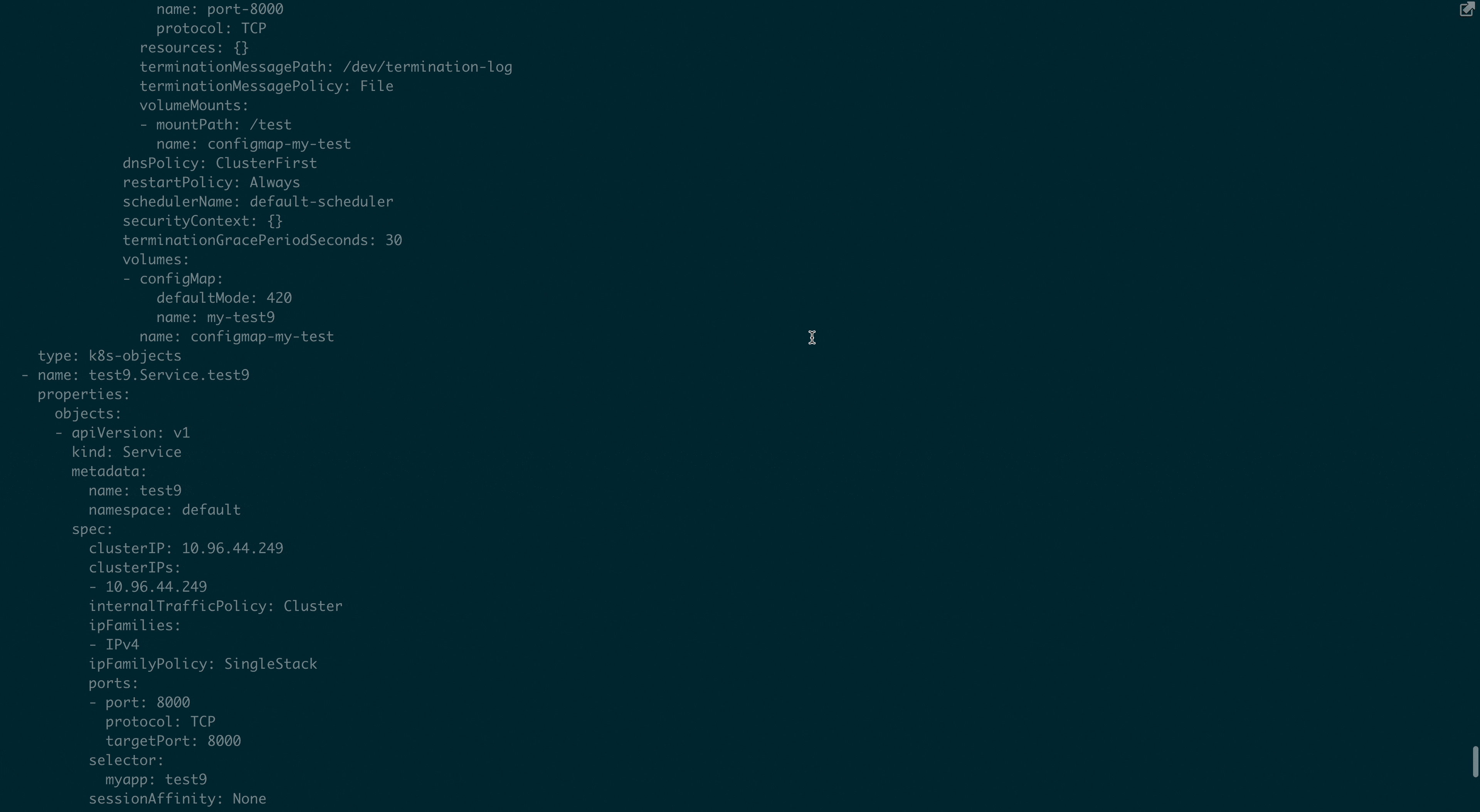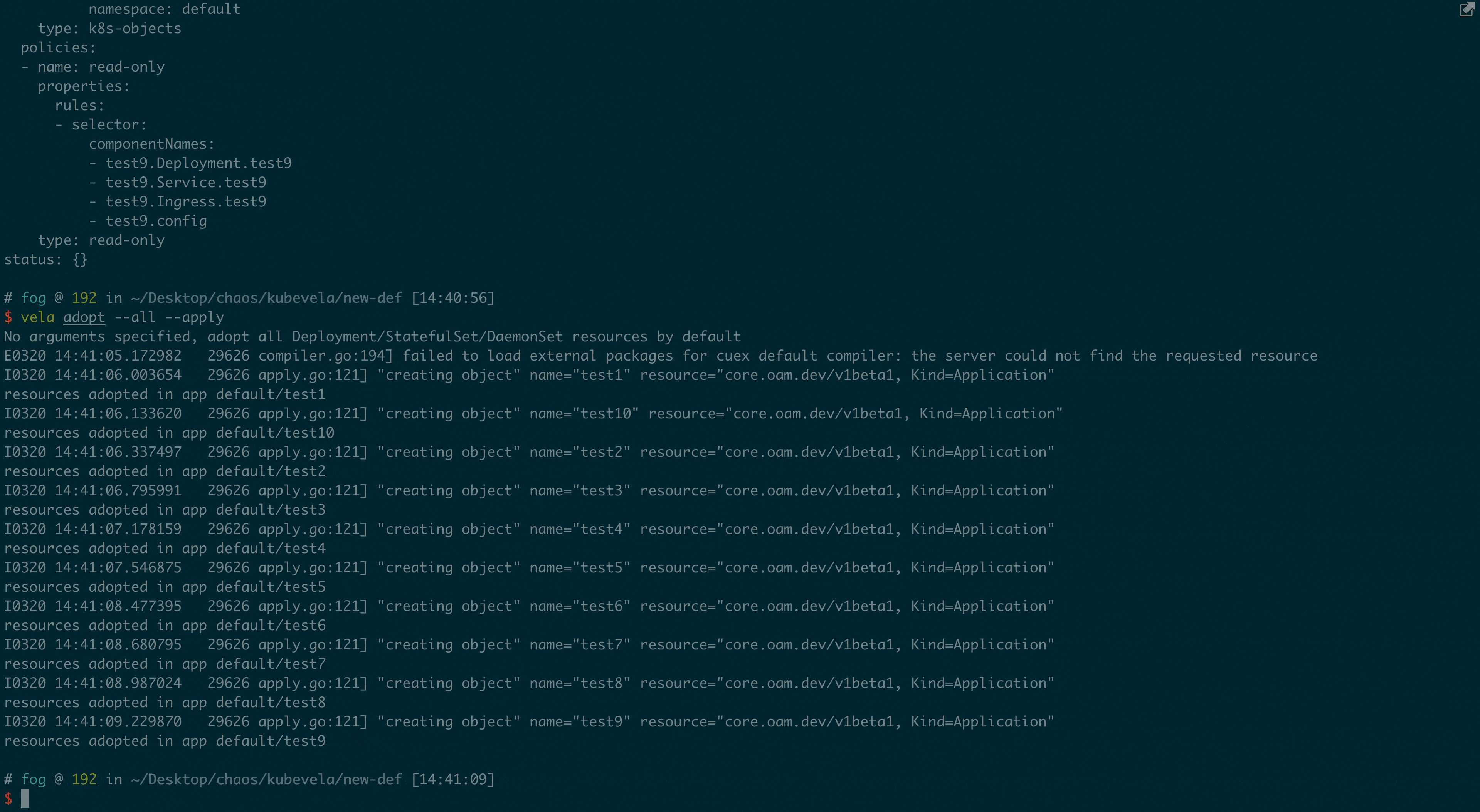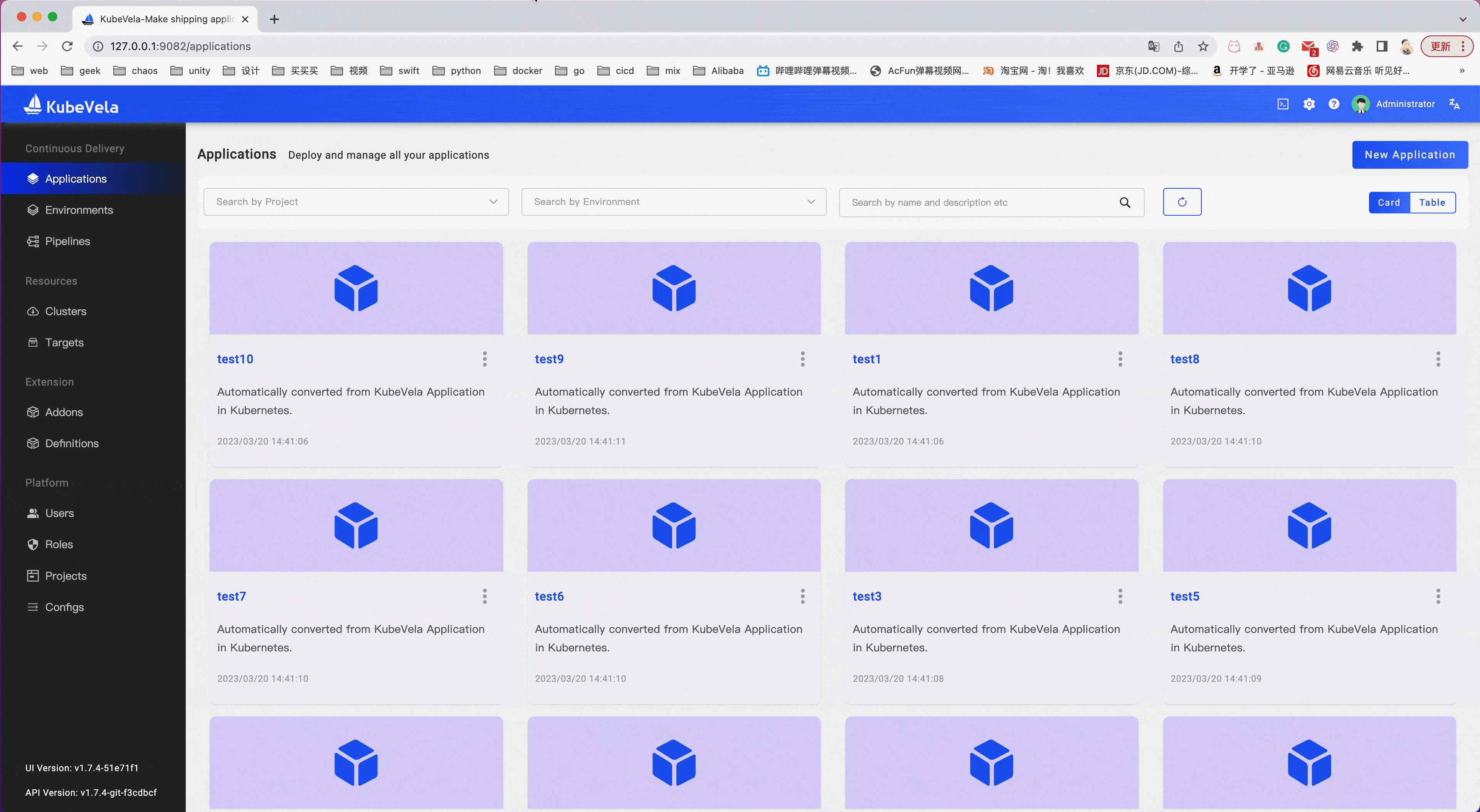
vela adopt --all --apply
这个命令会默认以内置资源拓扑规则识别当前命名空间下的资源及其关联关系,并进行应用接管。以一个 Deployment 为例,自动接管后的应用如下,除了主工作负载 Deployment 之外,还接管了它的对应资源,包括 ConfigMap,Service 以及 Ingress。
apiVersion: core.oam.dev/v1beta1
kind: Application
metadata:
name: test2
namespace: default
spec:
components:
- name: test2.Deployment.test2
properties:
objects:
- apiVersion: apps/v1
kind: Deployment
metadata:
name: test2
namespace: default
spec:
...
type: k8s-objects
- name: test2.Service.test2
properties:
objects:
- apiVersion: v1
kind: Service
metadata:
name: test2
namespace: default
spec:
...
type: k8s-objects
- name: test2.Ingress.test2
properties:
objects:
- apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: test2
namespace: default
spec:
...
type: k8s-objects
- name: test2.config
properties:
objects:
- apiVersion: v1
kind: ConfigMap
metadata:
name: record-event
namespace: default
type: k8s-objects
policies:
- name: read-only
properties:
rules:
- selector:
componentNames:
- test2.Deployment.test2
- test2.Service.test2
- test2.Ingress.test2
- test2.config
type: read-only
演示效果如下:
如果你希望使用自定义资源拓扑关系纳管自定义资源,可以使用如下命令:
vela adopt <your-crd> --all --resource-topology-rule=<your-rule-file.cue>
“接管规则”灵活定义
鉴于 KubeVela 充分可扩展的设计原则,资源接管面临的工作负载、接管方式也各不相同,我们自然也设计了完全可扩展、可编程的工作负载接管方式。事实上,命令行的一键接管能力,也只是基于 KubeVela 可扩展接管规则的一种特例。其核心思想是通过 CUE 定义一种配置转换的规则,然后在执行 vela adopt命令时指定转换规则即可,如下所示。
vela adopt deployment/my-workload --adopt-template=my-adopt-rule.cue
这种模式仅适用于高阶用户,在这里我们将不做过于深入的展开。如果你想了解更多细节,可以参考工作负载接管的官方文档。
大幅性能优化
性能优化也是本次版本中的一大亮点,基于过往社区中各类用户不同场景的实践,我们在默认资源配额不变的情况下,将控制器的整体性能、单应用容量、应用处理吞吐量整体提升了 5 到 10 倍。其中也包含了一些默认配置的变化,针对一些影响性能的小众场景,做参数上的裁剪。
在单应用容量层面,由于 KubeVela 的应用可能会包含大量实际的 Kubernetes API,这往往会导致 Application 背后记录实际资源状态的 ResourceTracker 以及记录版本信息的 ApplicationRevision 对象超过 Kubernetes 单个对象的 2MB 限额。在 1.7 版本中,我们加入了 ztsd 压缩功能并默认开启,这直接将资源的大小压缩了近 10 倍。这也意味着单个 KubeVela Application 中能够支持的资源容量扩大了 10 倍。
除此之外,针对一些场景如记录应用版本、组件版本,这些版本记录本身会由于应用数量规模的上升而等比例倍数提升,如默认记录 10 个应用版本,则会按应用数量的十倍递增。由于控制器本身 list-watch 的机制,这些增加的对象都会占用控制器内存,会导致内存使用量大幅提升。而许多用户(如使用 GitOps)可能有自己的版本管理系统,为了避免内存上的浪费,我们将应用版本的默认记录上限从 10 个改成了 2 个。而对于使用场景相对小众的组件版本,我们则默认关闭。这使得控制器整体的内存消耗缩小为原先的 1/3。
除此之外,还有一些参数调整包括将 Definition 的历史版本记录从 20 个缩小为 2 个,将 Kubernetes API 交互的限流 QPS 默认从 100 提升到 200 等等。在后续的版本中,我们将持续优化控制器的性能。
易用性提升
除了版本核心功能和性能提升以外,这个版本还对诸多的功能易用性进行了提升。
客户端多环境资源渲染
dry run 是 Kubernetes 中很受欢迎的一个概念,即在资源实际生效之前,先空运行一下,校验资源的配置是否合法。在 KubeVela 中也有这个功能,除了校验资源是否可以运行,还能将 OAM 抽象的应用转换为 Kubernetes 原生资源的 API,能够在 CLI 客户端实现从应用抽象到实际资源的转换。而 1.7 中增加的功能,就是指定不同的文件做 dry run,生成不同的实际资源。
如我们可以将测试和生产两个不同环境的策略(policy)和工作流(workflow)写成不同的文件,分别为 "test-policy.yaml" 和 "prod-policy.yaml",这样就可以在客户端,对同一个应用指定不同环境的策略和工作流,生成不同的底层资源,如:
- 测试环境运行
vela dry-run -f app.yaml -f test-policy.yaml -f test-workflow.yaml
- 生产环境运行
vela dry-run -f app.yaml -f prod-policy.yaml -f prod-workflow.yaml
其中,app.yaml中的内容如下,指定了引用一个外部的工作流:
# app.yaml
apiVersion: core.oam.dev/v1beta1
kind: Application
metadata:
name: first-vela-app
spec:
components:
- name: express-server
type: webservice
properties:
image: oamdev/hello-world
ports:
- port: 8000
expose: true
traits:
- type: scaler
properties:
replicas: 1
workflow:
ref: deploy-demo
而 prod-plicy.yaml和 prod-workflow.yaml的内容分别如下:
apiVersion: core.oam.dev/v1alpha1
kind: Policy
metadata:
name: env-prod
type: topology
properties:
clusters: ["local"]
namespace: "prod"
---
apiVersion: core.oam.dev/v1alpha1
kind: Policy
metadata:
name: ha
type: override
properties:
components:
- type: webservice
traits:
- type: scaler
properties:
replicas: 2
apiVersion: core.oam.dev/v1alpha1
kind: Workflow
metadata:
name: deploy-demo
namespace: default
steps:
- type: deploy
name: deploy-prod
properties:
policies: ["ha", "env-prod"]
对应的,测试环境的 YAML 文件可以用同样的模式修改其中的参数,这个功能非常适用于将 KubeVela 用作客户端抽象工具的用户,结合 Argo 等工具做资源的同步。
应用删除功能增强
在许多特殊场景下,应用删除一直是一个比较痛苦的体验。在 1.7 版本中,我们加入一些简便的方式,针对各类特殊情况,支持应用的顺利删除。
- 在集群失联的特殊情况下删除部分对应工作负载:我们提供了一个交互式删除资源的方法,可以通过查看集群名称、命名空间、资源类型,来选择底层工作负载,摘除集群失联这类特殊场景下涉及的资源。
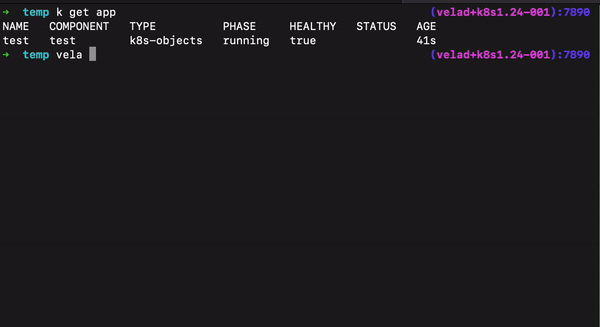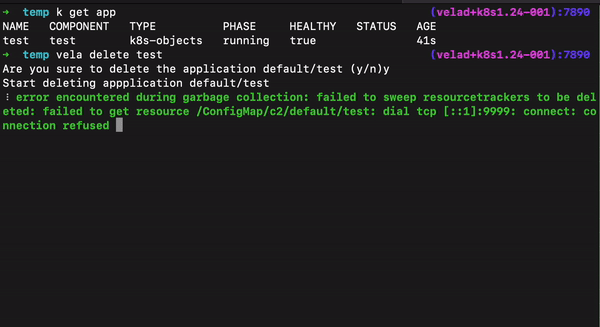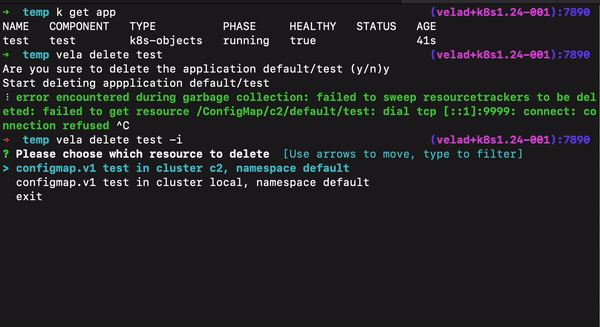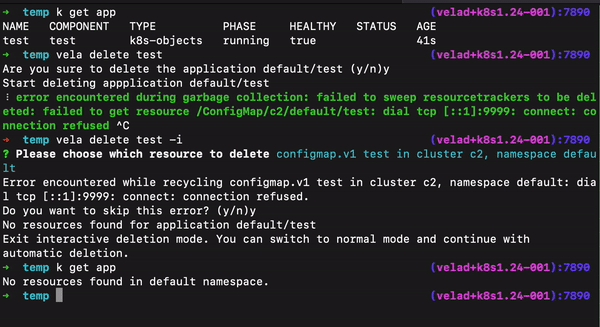
- 删除应用时保留底层资源:如果只想删除应用元数据而底层的工作负载和配置想保留,此时可以用
--orphan参数在删除应用是保留下层资源。 - 在控制器已经卸载的情况下删除应用。当你已经卸载了 KubeVela 的控制器,但发现还有残留应用没删干净时,你可以通过指定
--force来删除这些应用。
插件安装后自定义输出
对于 KubeVela 插件体系,我们新增了一个 NOTES.cue文件,可以允许插件的制作者动态的输出安装完成后的提示。比如针对 backstage 这个插件,其中的 NOTES.cue 文件如下:
info: string
if !parameter.pluginOnly {
info: """
By default, the backstage app is strictly serving in the domain `127.0.0.1:7007`, check it by:
vela port-forward addon-backstage -n vela-system
You can build your own backstage app if you want to use it in other domains.
"""
}
if parameter.pluginOnly {
info: "You can use the endpoint of 'backstage-plugin-vela' in your own backstage app by configuring the 'vela.host', refer to example https://github.com/wonderflow/vela-backstage-demo."
}
notes: (info)
这个插件的输出就会根据用户安装插件时使用的不同参数显示不同内容。
工作流能力增强
在 1.7 版本中,我们支持了更多细粒度的工作流能力:
- 支持指定某个失败的步骤做重试
vela workflow restart <app-name> --step=<step-name>
- 工作流的步骤名称可以不填,由 webhook 自动生成。
- 工作流的参数传递支持覆盖已有参数。
除此之外,我们新增了一系列新的工作流步骤,其中比较典型的步骤是 built-push-image,支持在工作流中构建镜像并推送到镜像仓库中。在工作流步骤的执行过程中,你可以通过 vela workflow logs <name> --step <step-name>查看执行日志。
VelaUX 功能增强
VelaUX 的控制台也在 1.7 版本中做了一系列增强包括:
- 支持更丰富的应用工作流编排能力,支持完整的工作流能力,包括子步骤、输入输出、超时、条件判断、步骤依赖等功能。应用工作流状态查看也更全面,可以查询历史工作流记录、步骤详情、步骤的日志和输入输出等信息。
- 支持应用版本回归,可以查看多版本之间应用的差异,选择某个版本回滚。
- 多租户支持,对多租户权限做更严格的限制,于 Kubernetes RBAC 模型对齐。
近期的规划
近期,KubeVela 1.8 正式版也在紧锣密鼓的筹划中,预计会在 3 月底正式跟大家见面,我们将在如下几个方面进一步增强:
- KubeVela 核心控制器的大规模性能和稳定性增强,针对控制器水平扩容提供分片(Sharding)方案,对多集群场景下万级别应用规模做控制器的性能优化和摸底,为社区提供一个全新的性能评测。
- VelaUX 支持开箱即用的灰度发布能力,对接可观测插件做发布过程的交互。与此同时,VelaUX 形成可扩展框架体系,对 UI 的定制提供配置能力,支持业务自定义扩展和对接。
- GitOps 工作流能力增强,支持 git 仓库同步的应用对接 VelaUX 的完整体验。
如果你想了解更多的规划、成为贡献者或者合作伙伴,可以通过参与社区沟通( https://github.com/kubevela/community )联系我们,期待你的加入!